
최신글
![[발표요약]what is transformer?](https://blog.kakaocdn.net/dna/MAJzl/btsNc7p5Ljv/AAAAAAAAAAAAAAAAAAAAAA1uxKlIzNTEOfOrTIn3ePFGOvWu1hJ1dtY29Nt7Yrl5/img.jpg?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1764514799&allow_ip=&allow_referer=&signature=a8gcH4ZX7nvdY4CR53DHL%2BRwouE%3D)
[발표요약]what is transformer?
DATA, AI
2025.04.08 10:12
4월 7일 발표한 transformer 관련 내용을 녹화하여 lilys ai(영상 자동요약 ai)로 요약한 내용입니다.오탈자나 오류로 잘못 요약된 부분이 있을 수 있습니다.
![[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback](https://blog.kakaocdn.net/dna/dwwE0B/btsMBgAYbUj/AAAAAAAAAAAAAAAAAAAAAHVe8kUMEXljEERBK6aJQXo2-wUIaCQHWlyjxevYMBUp/img.png?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1764514799&allow_ip=&allow_referer=&signature=ReBpT%2F59O44GxcQCtU1yh%2FVy%2Bug%3D)
[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback
Language Model
2025.03.02 22:18
최근 RLHF논문을 읽고, LLM Post-training 키워드를 전반적으로 정리했다.그러다 LoRA와 같은 Parameter Efficient Fine Tuning과 Preference Tuning이 목적성은 다르지만 출력을 개선하기 위해 파라미터를 업데이트 한다는 관점에서 보면 같은 방향성을 가진다고 생각했고, RLHF에 Adapter의 개념을 결합하면 효율적인 Preference Tuning이 되지 않을까? 하는 생각이 들었다. 서치 결과 Parameter Efficient Reinforcement Learning from Human Feedback; PE-RLHF라는 관련 논문이 2024년 9월에 프리프린트되어 있어 해당 논문을 리뷰한다. Abstract 해당 논문은 LORA: LOW-RANK ..
Reinforcement Learning : Understanding Fundamentals – From Key Concepts to Policy Gradient Methods
DATA, AI
2025.03.01 22:40
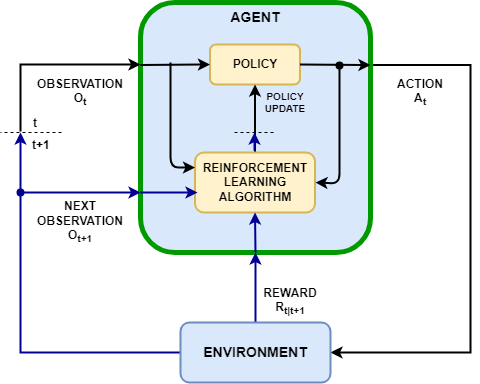
강화학습(Reinforcement Learning)은 기계학습의 한 분야로, 에이전트(Agent)가 환경(Environment)과 상호작용하면서 시행착오를 통해 최적의 행동 전략을 학습하는 방법이다. supervised learning처럼 정답 레이블에 의존하지 않고, 에이전트가 보상(Reward)을 최대화하는 방향으로 스스로 학습한다는 점이 특징이다. 이번 글에서는 강화학습의 기본 개념들을 정리하고, 정책 경사 방법의 일종인 REINFORCE 알고리즘을 정리한다.강화학습의 Key componentsAgent는 시점 $t$에서 관측 $O_t$을 받아 행동 $A_t$를 취하고, 환경은 다음 시점 $t+1$의 관측 $O_{t+1}$과 보상 $R_{t|t+1}$을 반환한다. 에이전트 내부의 정책(policy)..
![[논문리뷰] RLHF;Training language models to follow instructions with human feedback](https://blog.kakaocdn.net/dna/cS0gf1/btsMuwjO26o/AAAAAAAAAAAAAAAAAAAAAOQH6nKcwHNaT-mF8St2ZF3Bz5bVJCQsZIopzRxiH1gr/img.png?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1764514799&allow_ip=&allow_referer=&signature=%2FOhYpHTcNC1T2OtLq%2FYGWOlUM5c%3D)
[논문리뷰] RLHF;Training language models to follow instructions with human feedback
Language Model
2025.02.23 13:18
RLHF(Reinforcement Learning from Human Feedback)는 Pre-trained LLM이 사람의 기대나 선호도에 부합하도록 보상을 최적화하며 모델의 ‘Policy(응답 방식)’을 조정하는 방법이다. LLM Development Process Post-training 단계에 속하며, 사람의 지시(Instruction)에 따르도록 하는 명시적 의도와 편향이나 해로움을 최소화하려는 암묵적 의도 모두를 충족하도록 LM을 Alignment하는 것을 목적으로 한다. Background Reinforcement Learning의 keyword와 LLM 관점에서의 시각RLHF의 개념을 이해하기 위해 간단한 RL keyword를 정리한다.강화학습이란, agent가 Environment와 상..

우분투 환경에서 deepseek-r1 로컬 설치하기(open-webui, docker)
DATA, AI
2025.01.30 20:50
최근 발표된 DeepSeek-R1을 로컬 환경에서 실행한다면, Open WebUI 기반의 웹 인터페이스를 사용하면 더욱 편리하게 활용 가능하다. 이 글에서는 Ubuntu에서 Docker를 활용하여 Open WebUI를 설치하고, DeepSeek-R1 모델을 실행하는 방법을 정리한다. 들어가기 앞서,DeepSeek-R1은 크게 두 가지 버전으로 제공된다.원본 모델(DeepSeek-R1 671B): 671B(6,710억) 개의 파라미터를 가진 대형 모델로, 실행하려면 최소 400GB 이상의 VRAM이 필요하며, 현실적으로 로컬 환경에서 실행하는 것은 어렵다.Distilled Models: 원본 모델의 학습된 추론 능력을 비교적으로 파라미터가 적은 Qwen, Llama 모델에 전이시켜 성능을 최적화한 버전이다..
Insights
[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback
Language Model
2025.03.02 22:18
최근 RLHF논문을 읽고, LLM Post-training 키워드를 전반적으로 정리했다.그러다 LoRA와 같은 Parameter Efficient Fine Tuning과 Preference Tuning이 목적성은 다르지만 출력을 개선하기 위해 파라미터를 업데이트 한다는 관점에서 보면 같은 방향성을 가진다고 생각했고, RLHF에 Adapter의 개념을 결합하면 효율적인 Preference Tuning이 되지 않을까? 하는 생각이 들었다. 서치 결과 Parameter Efficient Reinforcement Learning from Human Feedback; PE-RLHF라는 관련 논문이 2024년 9월에 프리프린트되어 있어 해당 논문을 리뷰한다. Abstract 해당 논문은 LORA: LOW-RANK ..
[논문리뷰] RLHF;Training language models to follow instructions with human feedback
Language Model
2025.02.23 13:18
RLHF(Reinforcement Learning from Human Feedback)는 Pre-trained LLM이 사람의 기대나 선호도에 부합하도록 보상을 최적화하며 모델의 ‘Policy(응답 방식)’을 조정하는 방법이다. LLM Development Process Post-training 단계에 속하며, 사람의 지시(Instruction)에 따르도록 하는 명시적 의도와 편향이나 해로움을 최소화하려는 암묵적 의도 모두를 충족하도록 LM을 Alignment하는 것을 목적으로 한다. Background Reinforcement Learning의 keyword와 LLM 관점에서의 시각RLHF의 개념을 이해하기 위해 간단한 RL keyword를 정리한다.강화학습이란, agent가 Environment와 상..
SoundStream: An End-to-End Neural Audio Codec
etc.
2025.01.20 13:02
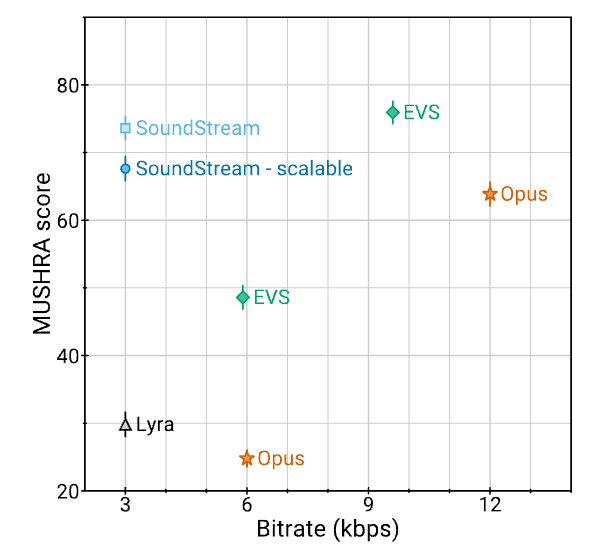
SoundStream이라는 새로운 신경망 기반 오디오 코덱을 제안한다. SoundStream은 Google이 개발한 오디오 처리 기술로, 딥러닝 기반의 신경망 오디오 코덱(neural audio codec)이다. SoundStream은 데이터를 압축하고 디코딩하는 압축 코덱의 역할을 한다. AbstractSoundStream은 fully convolutional 인코더/디코더와 Residual Vector Quantizer(RVQ)로 구성된 모델 아키텍처로,엔드-투-엔드 방식으로 학습된다.학습은 적대적 손실(adversarial loss)과 복원 손실(reconstruction loss)을 결합하여 양자화된 임베딩(quantized embeddings)으로부터 고품질 오디오 콘텐츠를 생성할 수 있도록 ..

GPT-1 : Improving Language Understanding by Generative Pre-Training
Language Model
2024.10.21 21:54
자연어 처리(NLP)는 최근 몇 년 동안 놀라운 발전을 이루었고, 그 중심에는 GPT-1 같은 주춧돌이 되는 모델이 있습니다. 이번 글에서는 GPT-1의 구조와 기능, 그리고 자연어 처리 작업에서의 뛰어난 성능을 살펴보겠습니다. 첫 번째 섹션에서는 기존 NLP 방법들이 가진 주요 문제점들을 다룹니다. 문맥 이해의 한계, 복잡한 작업 처리의 어려움 등 기존 모델들의 문제는 GPT-1 같은 새로운 접근법의 필요성을 높였습니다.두 번째 섹션에서는 GPT-1의 모델 구성과 학습 방식을 소개합니다. GPT-1은 다음 단어를 예측하는 방식을 통해 학습하며, 이를 통해 다양한 NLP 작업에 적용될 수 있습니다. 이 섹션은 GPT-1의 작동 원리를 이해하는 데 중요한 내용을 담고 있습니다.세 번째와 네 번째 섹션에서는..

BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
Language Model
2024.10.02 08:04
Background1. 기존 연구의 한계BERT 논문이 나타나기 이전에도 언어 모델을 사전 훈련한 후에 task에 대해서 feature-based 모델을 만들거나 fine-tuning하는 방식이 인기를 끌었다. BERT가 나타나기 이전에 나온 대표적인 모델은 GPT-1으로 많은 양의 데이터를 학습된 pre-trained model이며 fine-tuning을 통해 성능을 보장했기에 상당한 인기를 얻었다.그러나 GPT-1과 같은 기존 모델들은 오토레그레시브(Autoregressive) 방식을 사용하는 디코더 모델이기 때문에, LSTM이나 RNN처럼 결국에는 문제를 해결하기 위해서 문장을 학습할 때에 순차적으로( LTR; Left-to-Right ) 읽을 수 밖에 없다는 문제점을 지니고 있다. (추가로 ELM..
DATA / AI
[발표요약]what is transformer?
DATA, AI
2025.04.08 10:12
4월 7일 발표한 transformer 관련 내용을 녹화하여 lilys ai(영상 자동요약 ai)로 요약한 내용입니다.오탈자나 오류로 잘못 요약된 부분이 있을 수 있습니다.
Reinforcement Learning : Understanding Fundamentals – From Key Concepts to Policy Gradient Methods
DATA, AI
2025.03.01 22:40
강화학습(Reinforcement Learning)은 기계학습의 한 분야로, 에이전트(Agent)가 환경(Environment)과 상호작용하면서 시행착오를 통해 최적의 행동 전략을 학습하는 방법이다. supervised learning처럼 정답 레이블에 의존하지 않고, 에이전트가 보상(Reward)을 최대화하는 방향으로 스스로 학습한다는 점이 특징이다. 이번 글에서는 강화학습의 기본 개념들을 정리하고, 정책 경사 방법의 일종인 REINFORCE 알고리즘을 정리한다.강화학습의 Key componentsAgent는 시점 $t$에서 관측 $O_t$을 받아 행동 $A_t$를 취하고, 환경은 다음 시점 $t+1$의 관측 $O_{t+1}$과 보상 $R_{t|t+1}$을 반환한다. 에이전트 내부의 정책(policy)..
우분투 환경에서 deepseek-r1 로컬 설치하기(open-webui, docker)
DATA, AI
2025.01.30 20:50
최근 발표된 DeepSeek-R1을 로컬 환경에서 실행한다면, Open WebUI 기반의 웹 인터페이스를 사용하면 더욱 편리하게 활용 가능하다. 이 글에서는 Ubuntu에서 Docker를 활용하여 Open WebUI를 설치하고, DeepSeek-R1 모델을 실행하는 방법을 정리한다. 들어가기 앞서,DeepSeek-R1은 크게 두 가지 버전으로 제공된다.원본 모델(DeepSeek-R1 671B): 671B(6,710억) 개의 파라미터를 가진 대형 모델로, 실행하려면 최소 400GB 이상의 VRAM이 필요하며, 현실적으로 로컬 환경에서 실행하는 것은 어렵다.Distilled Models: 원본 모델의 학습된 추론 능력을 비교적으로 파라미터가 적은 Qwen, Llama 모델에 전이시켜 성능을 최적화한 버전이다..

GPU의 제한된 vram 환경에서 효율적으로 모델을 학습하는 방법
DATA, AI
2024.11.20 16:28
딥러닝 모델을 학습할 때 가장 현실적인 문제는 vram 부족이다. 필요한 vram이 물리적인 크기를 초과할 경우 OOM 오류가 뜨거나 블루스크린(MEMORY MANAGEMENT ERROR)가 뜨기도 한다. 이런 상황에서, vram 사용량에 크게 영향을 주는 배치사이즈를 직접적으로 늘리지 않더라도 메모리 사용량을 최적화하여 모델을 학습하는 방법에 대해 공부하고 정리한다. 문제인식현재 오픈소스 LLM을 LoRA 파인튜닝 하여 수능과 같은 수리논술문제 풀이에 최적화된 모델을 만드는 프로젝트를 진행하고 있다. 프로젝트와 데이터에 따라 크게 차이가 나지만 현재 진행중인 프로젝트에서 RTX 3090으로 파라미터 7~8B의 모델을 돌리면 vram 24GB 이상을 요구한다. 4비트로 양자화 하여 모델을 학습시켜도 파라..

huggingface로 협업하기
DATA, AI
2024.10.29 15:58
팀 기능과 함께 모델 버전 관리, 협업 및 배포 지원을 제공해 팀 단위로 머신러닝 모델을 관리하는 데 유용한 Hugging Face 사용법을 정리한다.Organization 생성Organization을 만들면, 여러 팀원이 하나의 허깅페이스 계정에서 협업할 수 있게 된다. 팀 단위로 모델과 데이터셋을 관리하여, 모든 멤버가 동일한 리소스에 접근하고 업데이트할 수 있고, 각 멤버에게 관리자, 편집자, 읽기 전용 등의 권한을 부여할 수 있어, 팀 내에서 역할에 맞게 접근 권한을 설정할 수 있다. 그러기 위해서1. 허깅페이스에 로그인한 후, 프로필 메뉴에서 "Create an Organization"을 선택2. Organization 이름과 설명을 입력하고 생성- 이때 Organization Username ..
Python

Python에서 .env 환경변수 파일 작성 및 관리
Python
2024.10.31 06:57
개발을 하다 보면 중요한 정보들을 코드 안에 직접 작성하는 것이 아닌, 외부 파일에 따로 저장하고 이를 가져오는 방식으로 관리하는 것이 필요합니다. 특히 API 키, 데이터베이스 비밀번호와 같은 민감한 정보는 .env 파일을 통해 관리하는 것이 가장 일반적입니다. 1. .env 파일이란?.env 파일은 환경변수를 저장하는 텍스트 파일로, 보통 프로젝트 루트 디렉터리에 위치하며 각 줄에 KEY=VALUE 형식으로 데이터를 저장합니다. 이를 통해 민감한 정보를 코드와 분리하여 보안성을 높일 수 있습니다. .env 파일의 내용은 다음과 같습니다. 2. Python에서 .env 파일 사용하기파이썬에서 .env 파일을 로드하고 사용할 수 있는 가장 일반적인 방법은 python-dotenv 라이브러리를 사용하는 것..

파이썬 : Closure(클로저), Currying(커링)
Python
2024.09.07 01:46
클로저(Closure) : 어떤 함수의 내부 함수가 외부 함수의 변수를 참조할 때, 외부 함수가 실행을 마친 후에도 내부 함수가 외부 함수의 변수를 참조할 수 있도록 값을 어딘가에 저장하는 함수이다. 클로저의 구성요소1. 외부 함수2. 외부 함수 내에 정의된 내부 함수3. 내부 함수가 외부 함수의 변수를 참조4. 외부 함수가 내부 함수를 반환 예제def outer_function(a): x = a + 2 def inner_function(y): return x + y return inner_function# outer_function 호출 및 정상 종료closure_instance = outer_function(10)# 종료된 outer_function의 변수 x 사용result ..

Lazy Evaluation : 파이썬의 객체지향
Python
2024.08.22 07:59
Lazy Evaluation이란?In programming language theory, lazy evaluation is an evaluation strategy which delays the evaluation of an expression until its value is needed (non-strict evaluation) and which also avoids repeated evaluations (by the use of sharing). -Lazy Evaluation, wikipedia Lazy Evaluation은 계산 결괏값이 필요할 때까지 계산을 늦추는 기법으로, 파이썬 뿐만 아니라 전반적인 컴퓨터 프로그래밍에서 쓰이는 용어이다. 실행과 동시에 구현하여 메모리에 보관하는 것이 아닌..
하드웨어

CPU와 GPU의 특성과 AI ASIC의 필요성
IT(Hardware)
2025.01.01 23:47
이글을 요약해서 정리하자면, CPU는 스칼라 연산에 최적화된 범용 프로세서이고, GPU는 SIMT 구조를 통해 대규모 병렬 연산에 특화되어 있습니다. AI 분야에서는 행렬 연산이 중요해 GPU가 주된 연산장치로 활용되어 왔으나, 통신병목과 효율성 등의 문제가 있습니다. 이를 극복하기 위해 TPU와 NPU 같은 AI 가속기가 활발히 연구되고 있습니다. CPU와 GPUCPU와 GPU는 모두 컴퓨팅을 담당하는 프로세서이지만, 설계방식과 기능적 특성에 큰 차이가 있습니다. 어떤 프로세서를 활용하느냐에 따라 처리 속도와 에너지 효율, 그리고 응용 가능한 분야가 달라지며, AI와 연결하여 설명하기 전에 우선적으로 CPU와 GPU에 대해 설명합니다. CPU와 GPU 연산의 차이 CPU는 스칼라 연산에 최적화된 범용..

3090 2way 워크스테이션 제작
IT(Hardware)
2025.01.01 23:31
이때까지 메인컴퓨터로 RTX3090이 단일로 들어간 SFF(Small Form Factor) 본체를 사용하였는데, GPU 성능을 올리고자 듀얼 GPU 시스템을 새로 제작했다. 소비자용 cpu에서의 제한된 pci 레인의 문제와 고용량의 파워서플라이 구성 등 생각보다 신경쓸 부분이 많았다. 우선 물리적으로 듀얼 GPU를 구성하기 위해 기존의 ITX규격에서 ATX규격의 메인보드로 교체를 진행했다.서버급 CPU가 아니면 pcie 레인이 24레인 남짓으로 제한되는데, 두개의 pcie 슬롯에 8-8-4레인으로 pcie레인을 분배해주는 보드가 많이 없어서 사용할 수 있는 보드를 찾는 것도 힘들었다. 대부분 16-4-4레인이나 16-4레인으로 구성되어 있었다. ATX보드는 7개의 pcie 슬롯이 나열될 수 있는 공간이..

온프레미스(On-premise) 웹 서버 환경 하드웨어 구성하기
IT(Hardware)
2025.01.01 22:57
기존에는 시놀로지를 통해 자기소개 사이트를 배포해서 사용했었다. 시놀로지에서 Docker를 쓰기에는 편리했지만, DSM OS의 제약과 NAS 리소스 점유로 인해 확장성과 유지보수에 한계가 있었다. CI를 위한 Jenkins를 Synology DSM 상에서 직접 사용하기는 까다롭다 느꼈고, 추후 여러 기능을 시도해볼 것까지 고려하면 별도의 바닐라 우분투 환경을 조성하는 것이 효율적이라고 판단하여 미니PC를 구매하고 우분투를 구성했다.해외직구를 통해 저전력 미니PC를 구입했다. 해당 PC는 인텔 셀러론 N100 프로세서와 8GB의 메모리를 탑재한 사양이다.기존에 웹페이지를 배포하던 J3355대비 코어수 및 클럭이 증가하면서 소비전력은 적은 프로세서이다.절대적인 출시년도도 6년의 차이가 있기 때문에 지원 명..
일상

포스팅 방식에 대한 고민, 블로그 글을 회고하면서
회고
2024.11.19 02:37
블로그 글 작성에 대한 고민최근까지 내 블로그의 모든 글은 아주 가끔적는 회고와 단순 개념 서술식의 글이 전부이다. 처음에는 공부한 내용을 단순하게 정리해서 블로그에 올리기만 하면 된다고 생각했다. 하지만 그 결과물은 여러 블로그에서 흔히 볼 수 있는 수천 개의 게시글 중 하나였다. 특히 최근에는 글쓰기에 특화된 ChatGPT 4o with canvas와 같은 모델들도 나오면서 단순한 지식나열은 점점 더 가치가 떨어질 것이라고 생각했다. 그래서 어떻게 하면 블로그 글을 의미있는 나만의 것으로 적어나갈 수 있을지 고민했다. 이때까지의 글을 회고하며대부분의 글에 내 생각이 담겨있지 않았다. 정보 전달력도 최근나온 GPT나 필력좋은 다른 글보다 결코 좋다고 장담할 수 있는 수준은 아니다. 다수의 타인을 잘 ..

도커와 GCP를 경험한 해커톤
회고
2024.11.02 20:14
제주도로 워케이션 가는 비행기안에서 짧게나마 저번주말 해커톤을 회고해본다. 10월 마지막 주말 학교에서 “교내 생활 문제 해결”이라는 주제의 해커톤이 있었다. 파트별 멤버는 PM 2명, 디자인 1명, FE(React) 2명, BE(Django) 2명, AI 3명이었고, 우리 팀은 기숙사생 룸메이트 매칭 서비스를 제안하였다. AI를 서비스에 어떻게 추가할지 고민하는 과정에서 나는 사람 간의 매칭이라는 큰 관점에서 데이팅 앱을 조사하였고, 튤립이라는 서비스의 가치관 기반 매칭 시스템을 적용하면서 AI를 서비스에 연결시키고자 하였다. 해당 앱의 매칭 알고리즘은 회원가입 시 약 30개의 객관실 질문에 대한 답변을 입력하게 되고, 그 답변을 기반으로 가장 비슷한 답변을 한 사람과 이어주는 방식이다. 나의 목표내가..
Github Actions을 사용한 Readme 업데이트 CI/CD 구축
Daily
2024.10.31 04:48
개발자로서 깃허브(GitHub)와 블로그는 단순히 기록을 남기는 공간이 아닙니다. 그것들은 자신의 성장과 성실성을 보여주는 중요한 수단으로도 쓰입니다. 하지만 이 두 채널을 꾸준히 관리하는 것은 결코 쉬운 일이 아니며, 특히 프로젝트에 몰두할 때에는 둘 중 한쪽이 소홀해지기 쉽습니다.그래서 깃허브 프로필을 통해 최근 블로그 활동을 보여주는 기능을 추가하고자 합니다. 이를 위해 깃허브 프로필의 README.md 파일에 블로그 게시글을 자동으로 불러오고, 새로운 게시글이 작성되면 깃허브에 커밋(commit)하여 최신 상태를 유지하는 방법을 적용했습니다. 이렇게 하여 깃허브와 블로그를 하나의 일관된 포트폴리오로 활용할 수 있기를 기대합니다.이 방식을 더 발전시켜 깃허브 프로필을 하위 마크다운 페이지로 나누고,..
네이버 부스트캠프 2번째 ODQA 프로젝트를 마치면서
회고
2024.10.28 10:39
프로젝트를 시작하면서 세운 목표지난 문장간 유사도 문석(STS)프로젝트에서는 베이스라인 개발, 모델리서치 및 실험, 앙상블 파트에 집중하였다. 프로젝트 시작 후 베이스라인 개발을 우선시하다 보니, 데이터분석과 활용에는 많이 신경 쓰지 못했던 아쉬움이 있었다. 그래서 이번 프로젝트는 데이터 분석과 데이터기반 성능향상에 초점을 맞추고자 했다.프로젝트에서 시도한 것에 대한 설명제공 데이터 분석우선 제공된 데이터분석을 진행하였다. 그 과정에서 그래프를 그릴 때 데이터의 분포와 데이터간 상관관계를 직관적으로 파악하기 위해 seaborn라이브러리를 사용하였고, 최대한 분석 목적에 맞는 그래프의 종류를 사용하려고 노력했다.우선 데이터의 구조를 판단하고, train, validation, test 데이터들의 분포를 확..
네이버 부스트캠프 2달차 회고하며
회고
2024.10.19 00:46
첫 한달동안은 나름 자유로움이 크다고 생각했다.대략 2달차로 들어서며, 커리큘럼이 꽤나 타이트해졌다.강의와 프로젝트가 함께 열리며, 두가지를 병행하다 보니 조금 더 타이트하다고 느꼈고,다른 사람들도 꽤나 이렇게 느낀 것 같았다.강의 자체는 큰 부담이 없지만,프로젝트를 함께하다보니 프로젝트의 성능(리더보드의 순위)을 목표로 하게 되면 성능향상에 많은 시간을 쏟아 붓게 되어 시간을 먹히기 쉬울 것 같았다. 이론적 지식 학습(강의 수강)+실전지식(프로젝트 진행)의 밸런스를 잘 잡는게 굉장히 중요하다고 느꼈다. TBD
알고리즘