


자연어 처리(NLP)는 최근 몇 년 동안 놀라운 발전을 이루었고, 그 중심에는 GPT-1 같은 주춧돌이 되는 모델이 있습니다. 이번 글에서는 GPT-1의 구조와 기능, 그리고 자연어 처리 작업에서의 뛰어난 성능을 살펴보겠습니다.
첫 번째 섹션에서는 기존 NLP 방법들이 가진 주요 문제점들을 다룹니다. 문맥 이해의 한계, 복잡한 작업 처리의 어려움 등 기존 모델들의 문제는 GPT-1 같은 새로운 접근법의 필요성을 높였습니다.
두 번째 섹션에서는 GPT-1의 모델 구성과 학습 방식을 소개합니다. GPT-1은 다음 단어를 예측하는 방식을 통해 학습하며, 이를 통해 다양한 NLP 작업에 적용될 수 있습니다. 이 섹션은 GPT-1의 작동 원리를 이해하는 데 중요한 내용을 담고 있습니다.
세 번째와 네 번째 섹션에서는 GPT-1의 실험 결과와 분석을 다룹니다. 여러 NLP 작업에서의 성능과 한계를 실제 데이터로 확인하며, 모델의 강점과 약점을 파악할 수 있습니다.
다섯 번째 섹션에서는 GPT-1의 장단점을 정리합니다. 모델의 강점과 약점을 이해함으로써 실제 작업에서의 적용 가능성을 평가하고, 이를 효과적으로 활용하는 방법을 살펴봅니다.
마지막으로, GPT-1의 의의와 NLP 분야에 미친 영향, 그리고 미래 발전 가능성을 논의합니다. 이를 통해 GPT-1의 혁신적 접근법이 NLP의 발전에 어떤 의미를 가지는지 이해할 수 있습니다.
GPT-1의 핵심 개념을 파악하고, 이 모델이 어떻게 NLP 작업을 혁신하는지 이해합니다.
1. 기존 방법의 문제점
기존 언어 모델의 문제점은 무엇일까요? GPT-1은 이러한 문제를 해결하기 위해 등장했습니다. 언어 모델을 위한 데이터 구성을 생각해보면, Labeled Data의 양은 많지 않습니다. 이는 사람의 Labeling 작업이 필요하여 확보하기 어렵기 때문입니다. 반면, Unlabeled Data는 쉽게 대량으로 확보할 수 있습니다.
기존 언어 모델은 이러한 Unlabeled Data를 충분히 활용하지 못하고, Labeled Data를 사용한 Supervised Learning에 의존했습니다. GPT-1은 Unlabeled Data를 효과적으로 활용하기 위해 Generative Pre-Training 방법을 도입했습니다.
2. GPT-1 제안 방법
GPT-1이 Generative Pre-Training의 효과를 어떻게 누리는지 살펴보겠습니다. 이번 섹션에서는 GPT-1의 전체 구조(Architecture)와 Unsupervised Pre-Training, Supervised Fine Tuning, 그리고 Task별 Input 구성 방법을 다룹니다.
2-1. Architecture

GPT-1은 Transformer의 Encoder를 제외하고 Decoder만을 사용합니다. Transformer와 GPT-1의 구조를 비교하면 다음과 같습니다.
GPT-1은 Transformer의 Decoder 부분만을 사용하며, 이때 Cross Self Attention 부분은 제거됩니다. 이는 Cross Self Attention이 Encoder의 입력과 Decoder의 입력을 Cross Attention하는 역할을 하지만, GPT-1은 Encoder 없이 Decoder만 사용하기 때문입니다.
Encoder를 제외하고 Decoder만 사용하는 이유는 두 가지입니다. 첫 번째는 학습 원리 때문입니다. GPT-1은 다음 단어를 예측하는 방식으로 학습하는데, 이는 Decoder에 적합합니다.(반대로 BERT는 Transformer의 Encoder만 사용합니다.) 두 번째 이유는 간결성입니다. Decoder만 사용하면 모델 구조가 간결해지고, 연산량이 줄어듭니다.
GPT-1은 Decoder 12개를 쌓아 올린 구조로, 최종 Output에 Linear Layer와 Softmax를 이어주어 최종 Output Probability를 출력합니다.
2-2. Unsupervised Pre-Training
GPT-1의 핵심은 Unsupervised Pre-Training입니다. 이는 GPT-1부터 GPT-3, InstructGPT, ChatGPT까지 이어지는 GPT 시리즈의 공통된 학습 철학이며, BERT 등 다른 LLM들과 차별화되는 점입니다.
GPT-1은 다음 단어를 맞추는 방식으로 학습합니다. 이를 Next Word Prediction이라고 하며, 수식으로 간단하게 표현됩니다. 예를 들어, '나는 오늘 학교에 가서 수업을 듣는다'라는 문장이 있다면, GPT-1에 '나는 오늘 학교에'라는 문장을 입력하고 다음에 나올 단어를 예측하도록 학습합니다.
이를 논문에서는 Next Word Prediction이라고 표현하는데요. 수식으로는 간단하게 이렇게 표현됩니다.

2-3. Next Word Prediction의 효과
GPT 시리즈는 모두 다음 단어를 예측하는 방식으로 학습하며, 그 성능이 매우 뛰어납니다. 이러한 학습 방식이 효과적인 이유는 다음과 같습니다.
첫째, 언어 구조를 학습하게 됩니다. 모델은 단어의 배치와 확률을 학습하여 언어의 구조와 문법을 이해합니다.
둘째, 문맥을 이해하게 됩니다. 다음 단어를 예측하려면 문맥을 이해해야 하므로, 모델의 문맥 이해 능력이 향상됩니다.
셋째, 다양한 언어 패턴을 학습합니다. 다양한 종류의 Unlabeled Data를 통해 모델은 다양한 언어 특성과 패턴을 학습하며, 인간과 유사한 언어 능력을 얻게 됩니다.
넷째, 전이 학습의 유용성입니다. Pre-Training을 완료한 모델은 Fine Tuning 작업을 통해 특정 Task에 맞게 재학습됩니다. Pre-Training은 특정 문제에 치우치지 않으면서 언어의 일반적인 이해 능력을 향상시키므로, 다양한 Task에 적합한 형태로 모델을 학습시킬 수 있습니다.
2-4. Supervised Fine Tuning
Pre-Training을 마친 모델은 각 Task에 맞도록 Fine Tuning을 합니다. 이 과정은 Supervised Learning 방법으로 이루어지며, Labeled Dataset을 사용합니다. Loss 함수는 다음과 같이 표현됩니다. 또한, Pre-Training Loss도 추가하여 함께 학습합니다.

또한, Pre-Training Loss도 추가하여 함께 학습합니다.
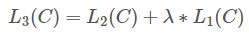
2-5. Task Specific Input Transformations
Task별로 Fine Tuning 시 Input Data는 어떻게 구성할까요? 예를 들어, 문장 분류(Classification) 문제와 유사도 측정(Similarity) 문제의 Input Data 구성은 다릅니다.
먼저 Classification 문제는 입력받은 텍스트를 분류하는 문제입니다. 예를 들어, 스팸 메일 분류 문제에서는 메일 내용을 입력으로 주고, 모델은 스팸 여부를 판단합니다.
다음으로 Textual Entailment 문제는 두 문장의 관계를 분류하는 문제로, 세 가지로 분류합니다: 함축(Entailment), 모순(Contradiction), 중립(Neutral). 이 경우 첫 번째 문장(Premise)과 구분자(Delim), 두 번째 문장(Hypothesis)을 구성해 모델에 입력합니다.
Similarity 문제는 두 문장의 유사도를 측정하는 문제입니다. 두 문장을 각각 모델에 입력한 뒤 나온 Representation을 통해 최종 유사도 값을 출력합니다.
Multiple Choice 문제는 Question Answering과 Commonsense Reasoning 문제로, Context와 Answer로 구성됩니다. 예를 들어, '서울은 대한민국의 수도입니다. 이 도시는 한강을 중심으로 확장되어 있습니다. 대한민국의 수도는 어디입니까?'라는 질문에 대해 '서울'이라는 답을 출력하도록 학습합니다.
3. 실험 결과
다음은 GPT-1의 실험 결과를 통해 제안 방법의 효과를 살펴보겠습니다.
3-1. Natural Language Inference
먼저 Natural Language Inference 실험 결과입니다.

모든 데이터셋에서 기존 방법들보다 성능이 좋은 모습을 볼 수 있습니다.
3-2. Question Answering and Commonsense Reasoning
다음은 Question Answering과 Commonsense Reasoning 실험 결과입니다.

모든 데이터셋에서 기존 방법들 대비 가장 좋은 성능을 확인할 수 있습니다.
3-3. Semantic Similarity & Classification
다음은 Semantic Similarity와 Classification 실험 결과입니다.

대체로 좋은 성능을 보여주고 있습니다.
아직 BERT와 같은 인코더 기반 모델이 나오기 전이라 STS, NLI와 같은 Task에서 SOTA에 가까운 모습을 보여주고 있습니다.
4. 분석
다음은 여러 실험을 통해 GPT-1을 분석한 내용을 살펴보겠습니다.
4-1. Layer 개수에 따른 성능 및 Zero Shot 성능
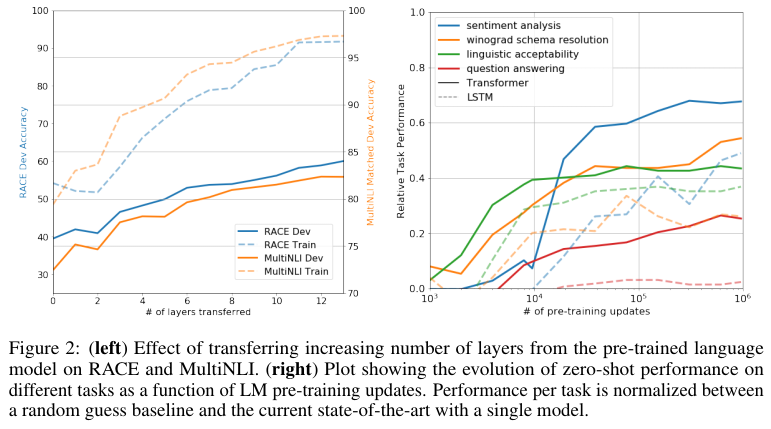
왼쪽 그래프는 Transfer에 사용한 Layer 개수에 따른 성능을 보여줍니다. 사용한 Layer의 개수가 많을수록 성능이 좋아지는 모습을 볼 수 있습니다. 이는 Pretrained 정보를 많이 사용할수록 Fine Tuning 시 성능이 좋아진다는 의미입니다. 즉, GPT-1에서 제안한 다음 단어 예측 학습 방법은 대부분의 Down Stream Task에 적합하다고 할 수 있습니다.
오른쪽 그래프는 Zero Shot 성능을 측정한 결과입니다. Pre-Training을 많이 진행했을수록 대부분의 Task에서 성능이 좋아지는 것을 확인할 수 있으며, Transformer 구조가 LSTM보다 우수함을 알 수 있습니다.
4-2. Ablation 실험 결과

Ablation 실험 결과를 통해 세 가지 교훈을 얻을 수 있습니다.
첫째, L1 Auxiliary Objective의 효과입니다. Fine Tuning 과정에서 Loss 함수를 Pre-Training Loss와 함께 사용하는 방법인 L1 Auxiliary Objective는 큰 데이터셋(NLI, QQP 등)에서는 도움이 되지만, 작은 데이터셋에서는 효과가 크지 않습니다.
둘째, LSTM과의 비교입니다. LSTM을 사용할 경우 전체적으로 성능이 크게 하락하는 모습을 보입니다. 이를 통해 Transformer 구조의 우수성을 확인할 수 있습니다.
셋째, Pre-Training의 효과입니다. Pre-Training을 생략할 경우 성능이 크게 하락하는 것을 볼 수 있습니다. 이는 GPT-1의 Pre-Training 방식이 매우 효과적이며, 성능에 큰 영향을 미친다는 것을 의미합니다.
5. 장단점
다음으로 여기까지 정리한 GPT-1 논문을 토대로 GPT-1의 장단점에 대해 생각해보겠습니다.
5-1. 장점
첫 번째 장점은 전이 학습의 효율성을 높인 방법이라는 것입니다. 즉, 강력한 Pre-Training 방법을 제안한 것이라고도 할 수 있습니다. 실험 결과를 통해 GPT-1의 Pre-Training 효과가 매우 강력하다는 것을 확인할 수 있습니다. Pre-Training 없이 Fine Tuning만 진행했을 때 성능이 크게 하락하는 모습을 볼 수 있었습니다. 이렇게 강력한 Pre-Training 덕분에 Task별 Fine Tuning을 통해 모델은 좋은 성능을 가질 수 있었습니다.
두 번째 장점은 Task별 최소한의 엔지니어링이 필요하다는 것입니다. GPT-1의 Pre-Training은 매우 강력한 효과를 발휘하며, Fine Tuning 과정에서도 모델의 구조를 크게 변경하지 않고 진행할 수 있어 이러한 강력한 Pre-Training 효과를 그대로 사용할 수 있습니다.
세 번째 장점은 강력한 성능입니다. 실험 결과를 통해 살펴본 것처럼 Pre-Training과 Fine Tuning을 거친 GPT-1의 성능은 대부분의 데이터셋에서 SOTA(State Of The Art)를 기록했습니다.
5-2. 단점
하지만 GPT-1에는 단점도 존재합니다.
첫 번째 단점은 많은 계산량으로 인한 높은 계산 비용입니다. 이는 이후에 나온 LLM들과 비교하면 작은 연산량이지만, 당시에는 가장 큰 연산량을 요구하는 방법이었습니다.
두 번째 단점은 Task별 Fine Tuning의 어려움입니다. 이후 발표된 모델들은 Fine Tuning 없이도 사용할 수 있는 방법을 사용해 이 단점을 해결했습니다. 하지만 GPT-1은 직접 Fine Tuning을 해야 하므로 일반화 능력이 떨어질 수 있는 한계가 존재합니다.
6. 의의
GPT-1은 언어 모델의 새로운 패러다임을 제시했다는 점에서 중요한 의의를 가집니다. 기존 방법과 달리 강력한 Pre-Training 방법을 제시하며 새로운 접근 방법을 제안했습니다. 이는 이후 LLM 모델들에게 새로운 연구 방향을 제시했습니다.
7. 마치며
기존 방법의 한계를 극복하기 위해 탄생한 GPT-1은 그 자체로 많은 가능성과 잠재력을 지니고 있습니다.
GPT-1의 모델 구성과 학습 방법을 자세히 알아보며, 이 모델이 어떻게 다양한 자연어 처리 작업에서 뛰어난 성능을 발휘하는지 이해할 수 있었습니다. 실험 결과와 분석을 통해 이러한 성능이 실제로 어떻게 나타나는지도 확인할 수 있었습니다.
물론, GPT-1도 완벽하지 않습니다. 이 모델의 장단점을 신중하게 검토하면서, 실제 작업에 어떻게 적용할 수 있을지 고민해야 합니다.
마지막으로, GPT-1의 의의를 되짚어보면, 이 모델은 자연어 처리의 미래를 예측하는 중요한 단서를 제공합니다. GPT-1과 같은 모델들은 앞으로도 계속 발전하며, 자연어 처리 분야의 다양한 문제와 도전 과제를 해결하는 데 중요한 역할을 할 것입니다.
'Insights > Language Model' 카테고리의 다른 글
개발새발라이프
hi there🙌
-
![[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdwwE0B%2FbtsMBgAYbUj%2FAAAAAAAAAAAAAAAAAAAAAHVe8kUMEXljEERBK6aJQXo2-wUIaCQHWlyjxevYMBUp%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DY00yca2wGCVRIum%252FfnR9gwju010%253D) [논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback2025.03.02
[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback2025.03.02 -
![[논문리뷰] RLHF;Training language models to follow instructions with human feedback](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcS0gf1%2FbtsMuwjO26o%2FAAAAAAAAAAAAAAAAAAAAAOQH6nKcwHNaT-mF8St2ZF3Bz5bVJCQsZIopzRxiH1gr%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DsSfgc%252FBETrF4zTt0nSHUeMqA8KU%253D) [논문리뷰] RLHF;Training language models to follow instructions with human feedback2025.02.23
[논문리뷰] RLHF;Training language models to follow instructions with human feedback2025.02.23 -
 BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding2024.10.02
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding2024.10.02 -
 Attention Is All You Need(2017) : Transformer 등장2024.09.27
Attention Is All You Need(2017) : Transformer 등장2024.09.27