

이글을 요약해서 정리하자면, CPU는 스칼라 연산에 최적화된 범용 프로세서이고, GPU는 SIMT 구조를 통해 대규모 병렬 연산에 특화되어 있습니다. AI 분야에서는 행렬 연산이 중요해 GPU가 주된 연산장치로 활용되어 왔으나, 통신병목과 효율성 등의 문제가 있습니다. 이를 극복하기 위해 TPU와 NPU 같은 AI 가속기가 활발히 연구되고 있습니다.
CPU와 GPU
CPU와 GPU는 모두 컴퓨팅을 담당하는 프로세서이지만, 설계방식과 기능적 특성에 큰 차이가 있습니다. 어떤 프로세서를 활용하느냐에 따라 처리 속도와 에너지 효율, 그리고 응용 가능한 분야가 달라지며, AI와 연결하여 설명하기 전에 우선적으로 CPU와 GPU에 대해 설명합니다.
CPU와 GPU 연산의 차이

CPU는 스칼라 연산에 최적화된 범용 프로세서입니다. 예를 들어 CPU는 한 번의 클록 사이클(또는 한 번의 명령어)에 하나 혹은 극히 제한된 수의 연산을 수행할 수 있습니다. 물론 SIMD(Single Instruction Multiple Data) 기술이 발전함에 따라 SSE나 AVX와 같은 확장 명령어 세트를 사용하면, CPU는 단일 명령을 통해 여러 개의 데이터(벡터)를 한 번에 처리할 수 있습니다. 이를 통해 동일한 연산을 반복적으로 수행해야 하는 상황에서 성능을 높일 수 있습니다. 다만 CPU의 SIMD 방식은 레지스터의 크기가 제한적이고, 코어 수 자체도 GPU만큼 많지 않기에 무작정 확장하기에는 한계가 있습니다.

반면 GPU는 그래픽 연산을 고속으로 처리하기 위해 탄생하였습니다. 1280*720 HD해상도 기준 921,600개 픽셀의 출력을 1초에 수십번씩 갱신하기에 CPU의 클록당 단일 연산으로는 적합하지 않았기 때문입니다. 그렇게 탄생한 GPU는 대규모 병렬 처리가 필요한 작업 전반으로 활용 폭을 넓혀왔습니다.
고속으로 많은 연산을 처리하기 위해 GPU는 SIMD 기술을 하드웨어적·소프트웨어적으로 보다 확장된 형태라 볼 수 있는 SIMT(Single Instruction, Multiple Threads) 모델을 따르게 되었습니다. 한 번의 명령어가 여러 스레드에 걸쳐 동시에 실행된다는 콘셉트 자체만 놓고 보면 SIMD와 흡사합니다. GPU 내부에서는 워프(warp)나 웨이브프런트(wavefront)라고 불리는 스레드 묶음 단위가 동일 명령어를 수행하면서도 각 스레드가 서로 다른 데이터를 처리합니다. 이러한 구조는 GPU가 그래픽이나 딥러닝 등에서 다루는 대규모 데이터를 병렬로 처리하는 데 최적화되어 있습니다.
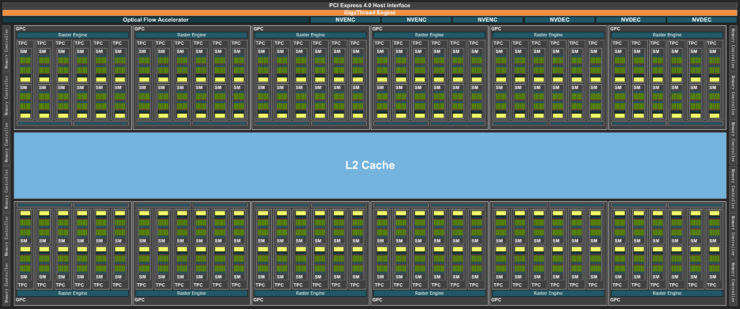

최신 발표된 Nvidia의 AD102 칩셋(RTX4090)의 다이어그램을 보면 코어가 백여개씩 그룹으로 묶여있으며, 각각의 코어 그룹은 백여개의 스레드가 들어있는 개별의 워프를 연산함을 알 수 있습니다.
정리하자면 CPU=범용 스칼라 처리, GPU=특화된 벡터 병렬 처리로 요약할 수 있습니다.
AI에서의 CPU와 GPU
CPU는 범용성이 매우 뛰어나 어떤 연산이든 처리해낼 수 있으며, 메모리 접근이나 프로그래밍의 유연성 측면에서도 장점이 큽니다. 다만 위에서 언급했던 복잡한 구조는 전력 소모를 높이고, 특정 작업(eg. 배열 연산이나 행렬 연산)을 반복해야 하는 경우에는 병렬 처리가 제한적이라 GPU보다 성능이 떨어집니다. 반면 GPU는 SIMT구조를 통해 행렬 연산이나 데이터 병렬성이 높은 작업에서 CPU보다 훨씬 더 빠른 처리 속도를 구현할 수 있습니다.
이러한 특징을 인공지능 분야에 비추어 보면 각 프로세서의 장단점이 매우 극명해집니다. AI연산은 대부분 행렬 연산과 대규모 병렬 처리를 기반으로 하기에, GPU가 상당히 유리한 경우가 많습니다. GPU가 수천개의 코어를 활용해 한 번에 수많은 연산을 병렬로 수행할 수 있기 때문입니다. 이는 특히 신경망 훈련 과정에서 매우 중요한데, 방대한 양의 데이터셋을 여러 번 학습시키기 위해서는 셀수없을 정도의 행렬 연산이 이루어지기 때문입니다. GPU는 이런 상황에서 CPU보다 훨씬 빠른 처리 성능을 보여주어 GPU가 오랜기간동안 주된 AI의 연산장치로 사용되었습니다.
결론적으로 CPU는 광범위한 용도를 아우르며 전통적인 프로그래밍 로직에 최적화되어 있고, GPU는 병렬화에 유리한 구조를 바탕으로 대규모 연산에 특화되어 있다고 할 수 있습니다.
GPU의 단점
GPU를 AI 연산에 사용할 경우 아래와 같은 단점들이 있고, 이를 보완하기 위해 TPU나 NPU같은 AI ASIC가 활발히 연구되며 활용되게 되고 있습니다.
대규모 행렬 연산에서의 비효율성
병렬 연산에 탁월하지만, 원래 그래픽 렌더링을 목적으로 발전해 왔기에 일반 병렬 처리를 위한 구조적 요소가 많고, 행렬 연산 외 다른 작업에도 대응해야 하는 범용성을 갖추고 있습니다. 그예로 여러 상황에 대응하기 위해 분기 예측, 캐시 계층, 스케줄러, 멀티프로세싱, 복잡한 실행 파이프라인 등 다양한 하드웨어를 갖추고 있습니다. 이는 다양한 연산을 유연하게 수행하는 장점이 있지만, AI 연산에만 한정지으면 전력과 면적의 낭비가 될 수 있습니다.
데이터 이동 과정에서의 병목
모델의 크기가 커지면서 AI연산에 대한 요구성능도 급속도로 증가하였습니다. 하지만 단일 GPU의 성능개선은 그만큼 빠르지 못했습니다. 따라서 다중 GPU를 사용하거나 GPU로 클러스터를 구성하는 형식으로 보완했습니다. 여기서도 새로운 장애 요인이 생겨나게 됩니다. 각각의 GPU는 CPU와 메인 메모리를 통해 통신하게 되고, 이때 PCI 익스프레스(PCIe) 레인이라는 규격을 통해 통신하게 됩니다. 이러한 통신과정에서 병목 현상을 일으킵니다. 또한 단일 CPU에 연결할 수 있는 PCIe 레인은 한정되어 있으므로 무한정 늘릴 수도 없어 여러개의 노드로 구성해야하고, 통신과정에서 더 큰 병목이 발생하게 됩니다.
결국 각 GPU가 대규모 행렬 연산을 빠르게 처리한다 해도, 중간 연산 결과를 서로 주고받거나 CPU를 거쳐 저장·로드하는 과정에서 속도가 떨어질 수밖에 없습니다.
이러한 이유로 AI ASIC가 활발히 연구되고 있으며, 해당 내용을 별도의 포스팅에서 설명합니다.

'IT(Hardware)' 카테고리의 다른 글
| 3090 2way 워크스테이션 제작 (3) | 2025.01.01 |
|---|---|
| 온프레미스(On-premise) 웹 서버 환경 하드웨어 구성하기 (0) | 2025.01.01 |
개발새발라이프
hi there🙌

