

이 논문은 트랜스포머 모델을 제안한 논문으로, 자연어 처리에서 RNN이나 CNN 없이도 주목 메커니즘(Attention)을 활용해 더 효율적이고 병렬 처리 가능한 방식으로 시퀀스를 처리한다는 내용을 담고 있다. 현대 대형 언어 모델(LLM)의 핵심적인 구조로, GPT나 BERT 같은 모델들의 근간이 되었다.

저자 TMI
Ashish Vaswani : 인도출신 구글 브레인 연구팀 소속이였다. 이후 3저자 Niki Parmar와 함께 Adept AI 창업후 새로운 스타트업 창업한 상태이다. 최근 Adept AI에서 80억개의 파라미터를 갖는 LLM인 Persimmon 8B모델을 오픈소스로 공개했다.
Łukasz Kaiser : 현재 OpenAI로 이직
Noam Shazeer : character.ai; 버추얼 챗봇 서비스 창업
Aidan N. Gomez: 비영리 단체 Cohere AI 창업
Llion Jones: 도쿄 AI 리서치 랩, Sakana AI 에 합류
Jakob Uszkoreit : 바이오 기술에 특화된 스타트업인 Inceptive Nucleics을 창업, 합성 분자를 이용하여 복잡한 기능을 수행할 수 있는 새로운 약물과 생물기술을Illia Polosukhin: 개발하는 것을 목표
Illia Polosukhin:블록체인 플랫폼인 NEAR Protocol을 설립
Abstract.
이때까지의 sequence transduction모델들은 LSTM과 같은 RNN기반 네트워크나 CNN네트워크를 기반으로 한다.
이때까지 최고의 성능을 보인 seq2seq모델을 포함한 모든 RNN 기반 모델을 배제하고 새로운 Transformer 아키텍쳐를 제안한다.
Introduction
1. 기존 모델의 한계를 지적
기존 RNN과 RNN기반 LSTM, GRU모델의 한계점을 지적한다. 이 한계들은 전 포스팅에 기재하였으니 전 포스팅 참고
2. 이를 해결하기 위한 최근 연구현황 소개
LSTM의 네트워크 구조가 복잡하고 연산 비용이 크다는 단점을 보완하기 위한 팩터라이제이션(factorization) 기법 연구를 소개(고차원 행렬을 작은 차원의 행렬로 분해하여 연산을 최적화하여 학습속도 증가 및 메모리 효율성 최적화)
하지만 순차적인 계산이라는 근본적인 제약해결X
3. 트랜스포머 제안
기존의 seq2seq에서 RNN과 함께 사용되었던 어텐션 메커니즘을 RNN없이 단독으로 사용하는 트랜스포머 아키텍쳐를 제안. 짧은 학습시간으로 번역 태스크에서 SOTA도달
Model Architecture
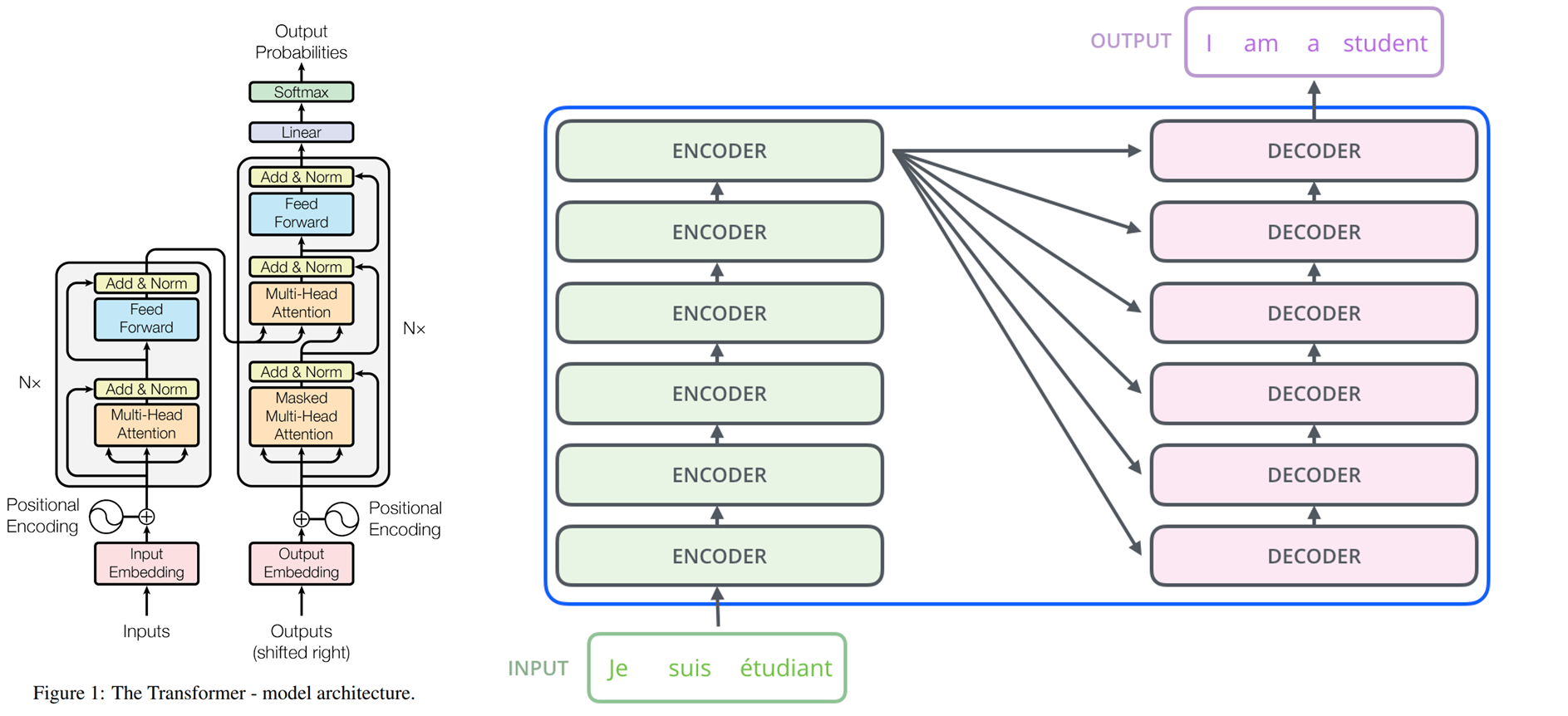
위의 모델을 이해하기 전에 간단하게 attention에 대해 짚고가자

동물과 그 동물의 다리갯수가 매핑된 해시테이블 T를 가정
T("강아지") = 4, T("닭")=2
만약 T("앵무새")를 쿼리로 던진다면? 오류발생
attention 메커니즘은 Soft matching을 통한 해시 테이블로 이해할 수 있다.
Query가 사자라고 했을 때, Query와 해시테이블의 각 Key 간의 유사도를 계산한 후 Value를 곱하게 된다.
앵무새-강아지간 내적유사도 : 0.02 X Value(4)=0.08
앵무새-닭간 내적유사도 : 0.92 X Value(2)=1.84
앵무새-문어간 내적유사도 : 0.019 X Value(8)=0.152
앵무새-오징어간 내적유사도 : 0.011 X Value(10)=0.11
앵무새-고양이간 내적유사도 : 0.03 X Value(4)=0.12
계산 후 값을 더하면 2.302가 된다.
앵무새(Query)와 닭(Key)간의 내적유사도가 제일 높았기 때문에 계산에 가장 큰 영향을 미쳤다.
따라서 해시 테이블에 앵무새가 없지만, 앵무새의 다리 개수는 2개(2.3개)라고 유추할 수 있다.

Self-attention

입력값에 각각 다른 W_q, W_k, W_v 가중치를 곱하여 벡터를 생성한다.
그 후 q와 k를 내적후 softmax를 취해서 유사도를 계산한다. value 벡터를 곱하면 attention이 출력된다.
이렇게 출력된 h는 자기자신은 물론 주변 정보를 포함하게 된다.
root(d_k)로 나눠주는 이유는 입력되는 벡터의 차원에 상관없도록 강건하게 만들어주기 때문이다.

Self Attention (Multi Head Attention)
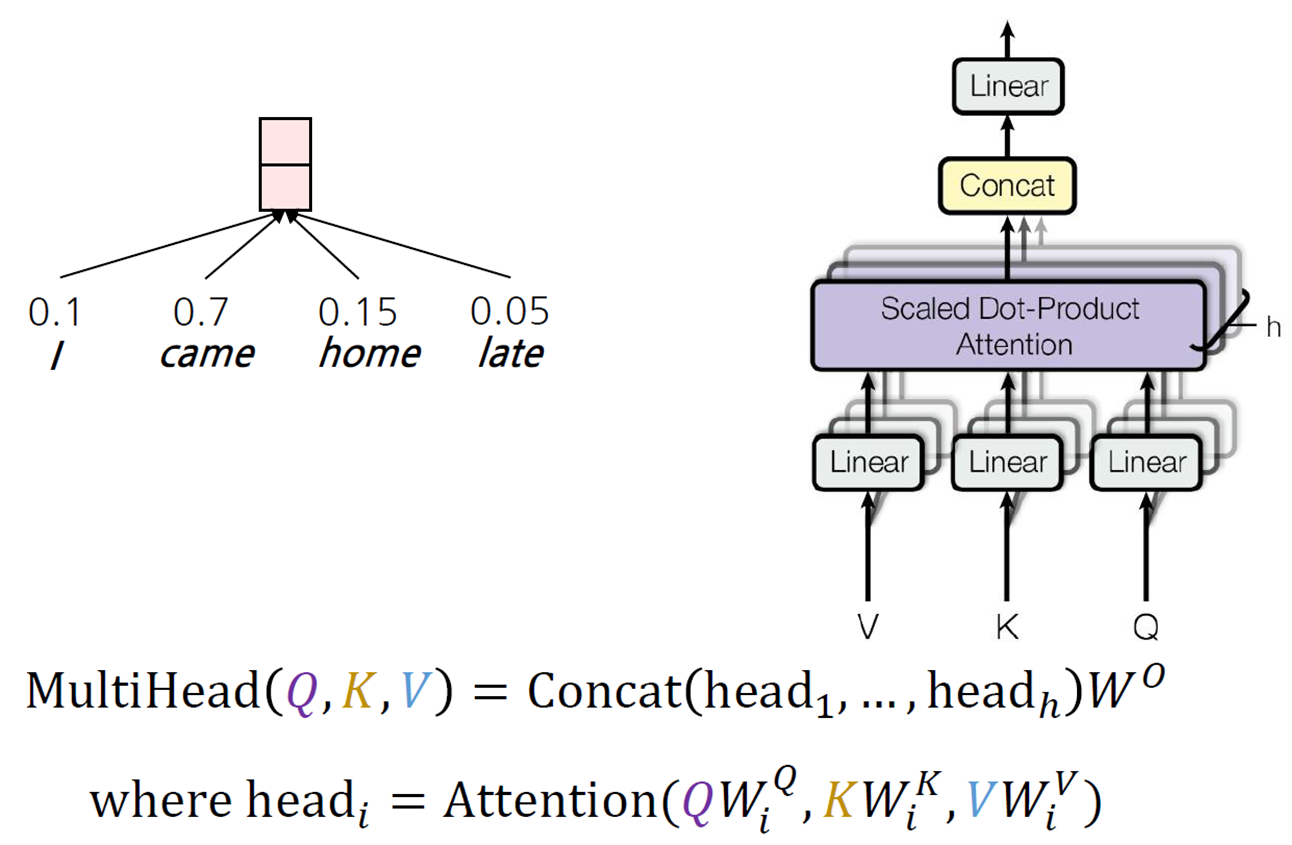
단일 어텐션은 하나의 표현만 할 수 있다.
예를 들어, 옆의 I came home late에서 위의 어텐션 스코어는 Query "I"와 다른 key간의 어텐션스코어라 가정하자.
이때 I와의 어텐션 스코어는 came이 가장 높게 나왔지만, 이는 행동에 기반한 어텐션 스코어일 뿐이다.
따라서, 다양한 관점에서의 어텐션 스코어를 계산하기 위해 Multi head attention을 제시한다.
이는 병렬적으로 처리되기 때문에 성능문제X

각각 다른 가중치들을 곱하여 여러개의 헤드가 생성되고, 이 헤드들이 concat되며 다양한 표현성을 갖는다.

이렇게 입력 X과 같은 크기의 Z가 출력된다면, 인코더 레이어가 하나 만들어지는 것이다.
인코더 레이어를 더 쌓아가면서 더 깊고 복잡한 관계를 학습할 수 있다. 아래는 그의 예시이다.

self attention의 경우에 입력길이가 짧을 때 효율적으로 계산된다.
병렬연산이 가능하므로 계산시간복잡도가 1에 불과하다.
또한 RNN과 같이 순차적으로 계산되는 것이 아니기 때문에, 특정 단어까지 접근하는 시간 역시 1이다.
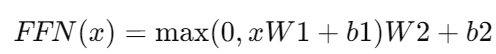
이후 비선형성을 추가 하기 위해 ReLU 활성화 함수로 구성된 Feed-Forward 네트워크를 통과하게 된다.
sinusoidal Positional Encoding
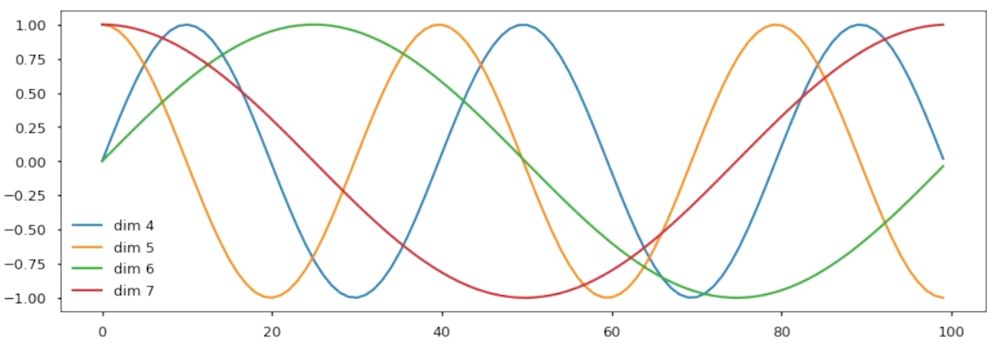

트랜스포머 아키텍쳐는 순서를 구분할 수 있는 능력은 없기 때문에 sinusoidal 함수를 이용하여 위치의 차이를 계산
디코더에서는
학습이 아예 안된 초반에 잘못된 추론을 이어갈 수 있으므로 grown truth를 제공
하지만 치팅을 방지하기 위해 미래정보를 가림(masked attention)
결과적으로

en-de 번역에서는 제일 좋은 성능을, en-fr번역에서는 seq2seq을 앙상블한 모델 비교하여 적은 파라미터를 가지면서도 비슷한 성능을 가짐
이미지 출처
'Insights > Language Model' 카테고리의 다른 글
개발새발라이프
hi there🙌
-
![[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdwwE0B%2FbtsMBgAYbUj%2FAAAAAAAAAAAAAAAAAAAAAHVe8kUMEXljEERBK6aJQXo2-wUIaCQHWlyjxevYMBUp%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3Dp6njodc0BV7zVD0Kq7fwy1zQ%252Fok%253D) [논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback2025.03.02
[논문 리뷰]PERL(PE-RLHF); Parameter Efficient Reinforcement Learning from Human Feedback2025.03.02 -
![[논문리뷰] RLHF;Training language models to follow instructions with human feedback](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcS0gf1%2FbtsMuwjO26o%2FAAAAAAAAAAAAAAAAAAAAAOQH6nKcwHNaT-mF8St2ZF3Bz5bVJCQsZIopzRxiH1gr%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DVrawMlPVWEPYEe134roCHhSRlkQ%253D) [논문리뷰] RLHF;Training language models to follow instructions with human feedback2025.02.23
[논문리뷰] RLHF;Training language models to follow instructions with human feedback2025.02.23 -
 GPT-1 : Improving Language Understanding by Generative Pre-Training2024.10.21
GPT-1 : Improving Language Understanding by Generative Pre-Training2024.10.21 -
 BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding2024.10.02
BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding2024.10.02