입출력 형태에 따른 자연어 처리 Task의 이해
자연어 처리의 이해

자연어처리는 다양한 Task로 나뉘어질 수 있다.
이러한 Task에 따라 어떤 형태의 모델을 사용할지도 달라진다.
입출력 패턴에 따라 Task를 분류하여 봄으로써, 자연어처리 Task와 모델별 입출력패턴 특징을 알아본다.
모델의 종류
1. Encoder Only Model

입력 토큰 벡터를 Encoder Block이 학습하여 고정된 크기의 출력 토큰 벡터를 생성하는 모델이다.
대표 모델로는 BERT, RoBERTa, ALBERT와 같은 BERT계열 모델이 있다.

고정크기의 출력을 생성하므로, N21형태와 N2N형태의 입출력 패턴 Task에 적합하다.
2. Encoder-Decoder Model

입력 토큰 벡터 를 인코딩한 후, 그 인코딩된 정보를 바탕으로 디코더가 출력 토큰 벡터를 생성하는 구조이다.
대표 모델로는 Transformer, BART, T5 등등이 있다.

다양한 크기의 출력을 생성할 수 있기때문에 N2M task에서 효과적이다.
모델이 복잡하고, 많은 학습 데이터와 계산 자원이 필요하다.
3. Decoder Only Model

N2M task를 해결함에 있어서, 입력받는 인코더와 출력하는 디코더를 갖춘 인코더-디코더 모델 대신 디코더만 사용할 수 있다.
<SOS>토큰과 같은 출력시작 토큰 대신에 입력 토큰 벡터를 시드 텍스트(프롬프트)로 주어 모델이 텍스트 생성을 시작할 수 있는 초기 입력을 제공한다. 이때 입력 벡터들의 각 토큰은 별도로 처리되고, 각 토큰은 하나의 벡터로 인코딩되어 모델에 입력된다.
프롬프트는 모델이 출력을 생성할 수 있도록 초기 맥락을 제공하며, 그 이후 모델은 오토레그레시브 방식으로 시퀀스를 확장한다.

대표 모델로는 GPT-2, GPT-3, GPT-4이 있다.
매우 강력한 텍스트 생성 능력을 가지고 있으며, 대화형 AI나 창의적 텍스트 생성에 적합하다.
Encoder-Decoder Model모델 대비 효율적이다.
입출력패턴에 따른 Task
1. N21
입력 시퀀스가 여러 개의 단어, 문장 등으로 이루어져 있고, 그 입력 시퀀스를 처리한 후 하나의 값을 출력하는 방식이다.
A. Topic Classification
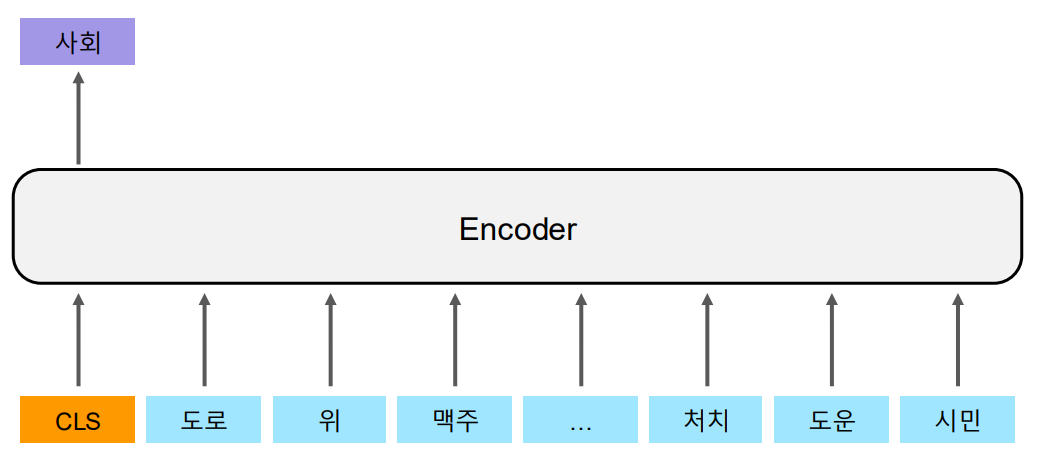
주어진 텍스트 시퀀스(문장이나 문서)를 하나의 클래스 레이블로 분류하는 작업이다.
감정 분석, 주제 분류, 뉴스 분류, 스팸 메일 분류, 감정 분류 등등이 있다.
문장 또는 문서가 입력되면(예: "이 제품은 정말 만족스러워요."), 세부 분류에 따라 긍정적(감정분류), 리뷰(주제분류)와 같은 단일 클래스 레이블이 출력된다.
B. Natural Language Inference; NLI(자연어 추론)

두 문장이 서로 같은 의미인지 아닌지 측정한다.
BERT의 경우 <SEP>토큰으로 두문장을 구분한다.
0~1 또는 0~Max Score 점수가 [CLS] 해당 최종 결과로 출력된다.
C. Sentence Similarity(문장 유사도 평가)

가설 문장과 전제 문장 간의 관계를 추론한다.
BERT의 경우 토큰으로 두문장을 구분한다.
진실 (entailment), 거짓 (contradiction), 미결정 (neutral)과 같은 단일 레이블이 출력된다.
2. N2N
다수의 입력 시퀀스(N)를 받아서 다수의 출력 시퀀스(N)를 생성하는 작업이다.
A. Named Entity Recognition;NER(개체명 분석)
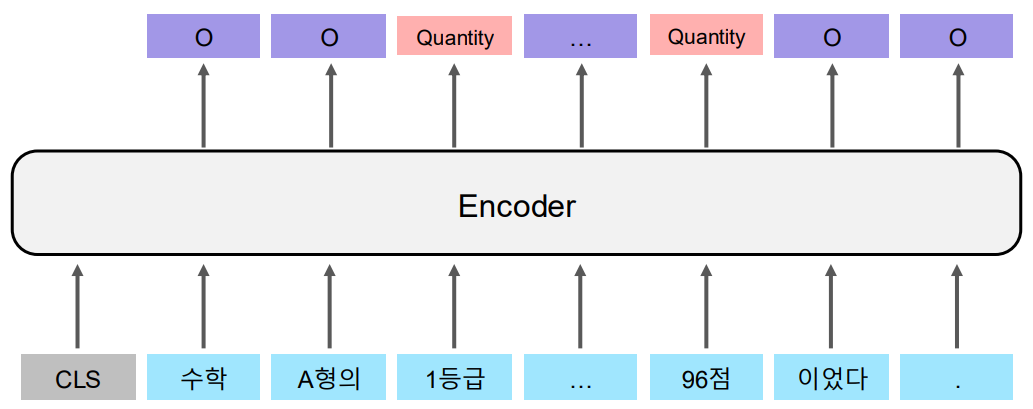
구조화되지 않은 텍스트에서 개체명의 경계를 감지하고 유형 분류
예를 들어 1등급과 96점은 양을 나타내는 속성임을 분석한다.
B. Morphology Analysis(형태소 분석)

입력되는 텍스트의 형태소(= 가장작은 의미단위) 분석한다.
각 단어의 형태소 및 문법적 성분을 나타내는 형태소 레이블 시퀀스를 출력한다.
한국어나 일본어와 같은 교착어는 하나의 단어 내부에 여러 문법적 의미가 포함되어 있기 때문에, 단어의 정확한 의미를 학습시키기 위해서 형서소 분석이 중요한 역할을 한다.
3. N2M
N개의 입력 시퀀스를 받아 M개의 출력 시퀀스를 생성하는 작업이다.
정말 다양한 Task가 있지만 4개정도 추려서 설명한다.
A. Machine Translation

인코더-디코더 구조에서, 인코딩을 통해 입력된 문장을 이해하고, 디코딩을 통해 새로운 시퀀스(번역된 문장)를 생성한다.
언어별 문장 길이가 다르기 때문에 N2M 패턴이 사용된다.
B. Dialog Model
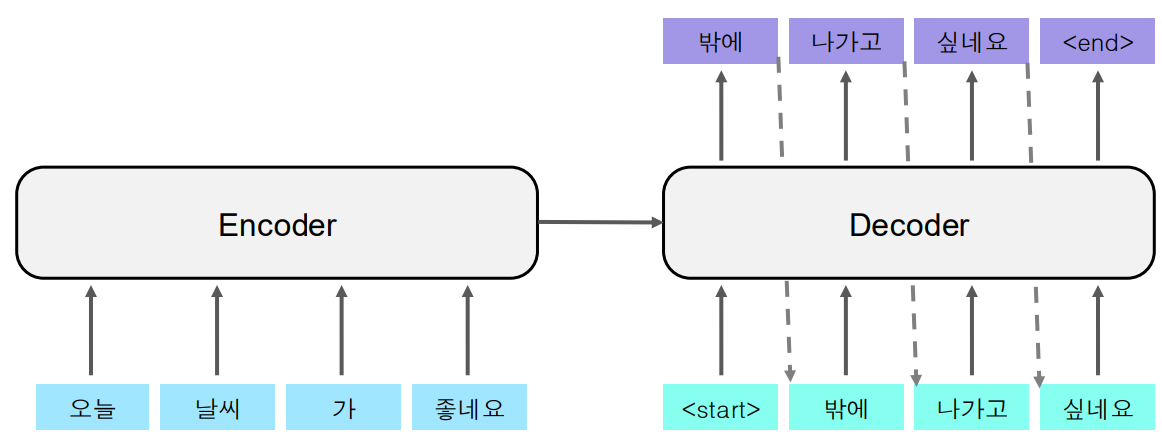
대화 모델은 사용자의 입력 문장을 받아 자연스러운 대화를 이어가기 위한 응답을 생성하는 작업이다. 입력과 출력의 시퀀스 길이는 다를 수 있으며, 대화의 맥락을 반영하여 응답을 생성한다.
C. Summarization

문서 요약은 긴 문서나 텍스트를 받아 중요한 정보만을 담은 짧은 요약문을 생성하는 작업이다.
D. Image Captioning
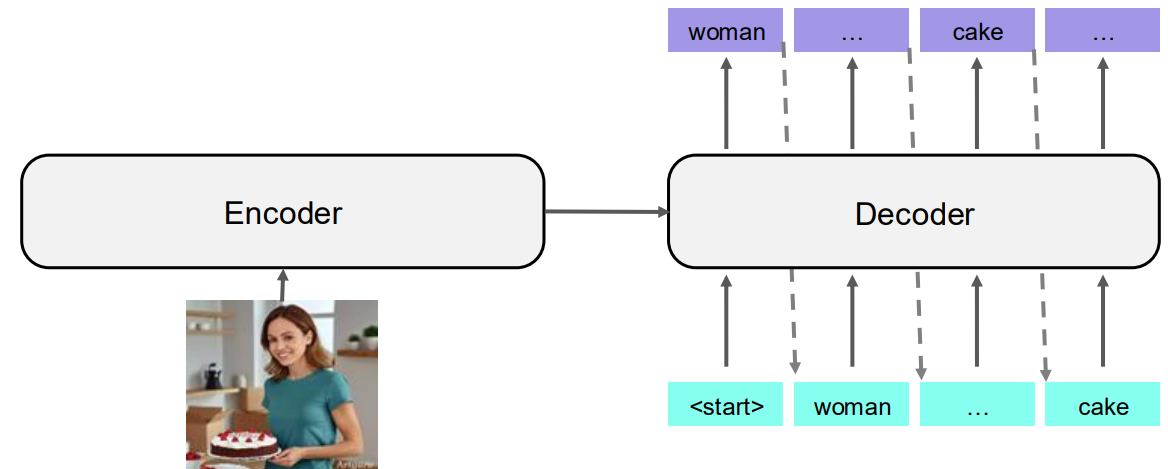
이미지를 받아 그 이미지의 내용을 설명하는 문장을 생성하는 작업이다. 여기서 입력은 이미지 자체이며, 출력은 이미지를 설명하는 자연어 문장이다.
